

智能軟件研究中心碩士生段旭榮獲ISSRE 2021最佳實踐論文獎
文章來源: | 發布時間:2021-11-03 | 【打印】 【關閉】
近日,中國科學院軟件研究所智能軟件研究中心武延軍、吳敬征課題組在基于深度神經網絡的靜態代碼分析研究中取得進展。該團隊提出了基于多類型和多粒度的語義代碼表示學習模型——MultiCode,解決了工業場景中涉及多需求的開發任務時面臨的開發開銷大、模型集成困難、可擴展性受限等問題,實現了在多需求工業場景下的高效開發和準確預測,在漏洞檢測、代碼克隆檢測等任務中得到了具體實踐,并在政府部門和互聯網企業中實際應用。
研究成果以MultiCode: A Unified Code Analysis Framework based on Multi-type and Multi-granularity Semantic Learning為題發表在軟件可靠性工程領域旗艦國際會議ISSRE 2021的Industry Track上。在此次會議投稿的226篇論文中,71篇論文被接受,其中僅有本研究1篇論文被評為最佳實踐論文。論文第一作者為課題組碩士研究生段旭。
基于深度神經網絡的靜態代碼分析方法通常在不同代碼分析任務中引入針對性設計,導致模型呈現高度多樣化的態勢。在工業領域,該現象會使開發者在開發涉及多需求的代碼分析平臺時,面臨開發開銷大、模型集成困難、可擴展性受限等問題。
針對上述問題,MultiCode模型能夠學習代碼中多種類型和粒度的語義信息,進而支撐多種代碼分析任務。團隊提出使用抽象語法樹、控制流圖、程序依賴圖等結構,對代碼中不同類型和粒度的語義信息進行建模,并利用樹神經網絡和圖神經網絡分別對不同的語義信息進行處理。在該過程中,MultiCode模型自底向上地先學習語句級別的表示,再基于該表示學習代碼段級別的表示。通過將該模型作為編碼器進行神經網絡構建,能夠有效適配于不同的代碼分析任務。在漏洞檢測和代碼克隆檢測任務上的評估結果表明,其能夠在不需要重新構建編碼器的情況下,在不同任務中有效地識別并區分不同類別代碼的語義,進而支撐多種任務上的預測。
該研究得到國家重點研發計劃、國家自然科學基金的支持。
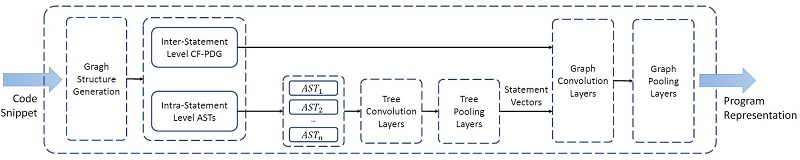
MultiCode基于多類型和多粒度的語義代碼表示學習模型框架

ISSRE 2021最佳實踐論文獎




