

軟件所在小樣本目標檢測方面取得進展
文章來源: | 發布時間:2023-02-27 | 【打印】 【關閉】
軟件所天基綜合信息系統重點實驗室研究團隊的論文“Disentangle and Remerge: Interventional Knowledge Distillation for Few-Shot Object Detection from A Conditional Causal Perspective”近日被人工智能領域頂級學術會議AAAI(Association for the Advancement of Artificial Intelligence)接收,第一作者為博士生李江夢、張雅楠。論文首次從因果理論的角度重新審視了小樣本目標檢測任務的知識蒸餾學習范式,并基于建立的結構因果模型,提出知識蒸餾方法“分離和重組”(D&R),以對相應的結構因果模型進行條件因果干預,在小樣本目標檢測任務上產生顯著的性能提升。
小樣本學習模型基于有限的標注數據學習表征,在圖像分類、目標檢測等多種任務中被廣泛應用。然而,小樣本目標檢測方法存在一個固有的缺陷,即有限的訓練數據使得模型不能充分地探索語義信息。為了解決這個問題,研究團隊將知識蒸餾引入到小樣本目標檢測學習范式中。實驗發現,在知識蒸餾的過程中,作為學生模型的小樣本目標檢測模型不僅會學到教師模型的知識來獲取語義信息,還可能學到教師模型的經驗錯誤而導致性能下降。研究團隊希望解決這個問題,以促進小樣本學習模型利用外部知識的能力。
研究團隊建立了結構因果模型。通過理論分析得到,輸入圖像和預測結果之間的因果效應需要以特定任務的分類知識為條件進行量化。此時,量化的結果可能由于外部知識而出現偏差。為此,研究團隊提出使用后門調整來消除混雜因子的干擾。具體來說,研究團隊基于基準方法的主分支引入了一個輔助分支。從參數固定的預訓練文本編碼器中獲得了特定維度的嵌入類別向量,并使用線性投影層將視覺特征轉化為相同維度的向量。在訓練基類時,以端到端的方式訓練特征提取器和線性投影層。在新類上進行微調時,引入了基于結構因果圖提出的損失函數。損失函數通過“解構”經典知識蒸餾損失函數并“重組”非混雜項得到。
該方法與多種不同的小樣本目標檢測算法在COCO和VOC兩個重要數據集上進行了對比,結果表明,與基準方法相比,新建模型在小樣本數據集VOC上的目標檢測性能平均提升了1.58%(以AP50作為評價指標),在小樣本數據集COCO上的目標檢測性能平均提升了0.68%(以mAP作為評價指標)。團隊還通過消融實驗證明了所提出方法的合理性。
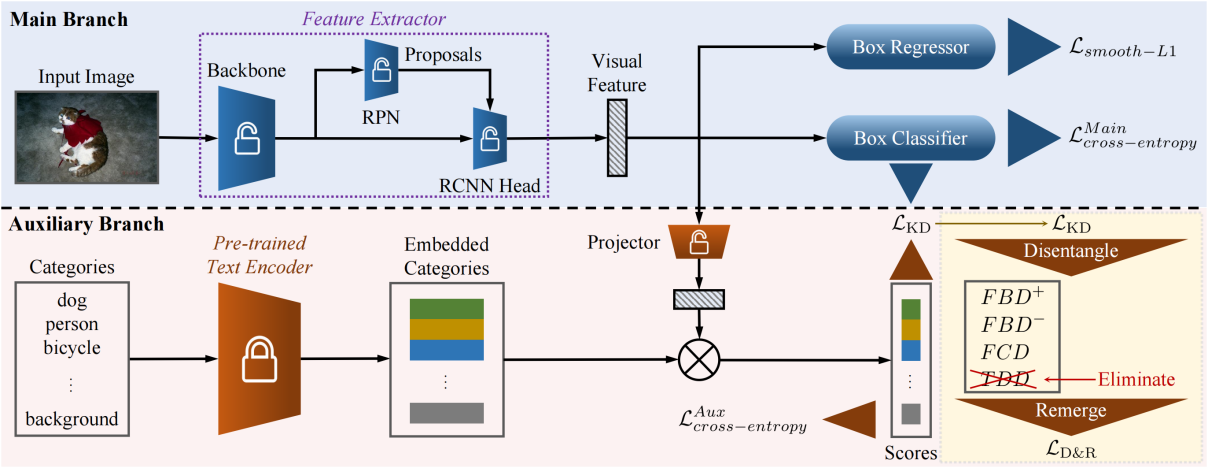
D&R框架圖
論文地址:https://arxiv.org/abs/2208.12681
模型地址:https://github.com/ZYN-1101/DandR




