

軟件所在自監督多視角表示學習方面取得進展
文章來源: | 發布時間:2023-08-28 | 【打印】 【關閉】
軟件所天基綜合信息系統重點實驗室研究團隊的論文Information Theory-Guided Heuristic Progressive Multi-View Coding近日被計算機科學領域頂級學術期刊Neural Networks接收,第一作者為特別研究助理李江夢。論文從信息論的角度重新審視了自監督多視角表示學習(Self-supervised multi-view representation learning),并建立了相應理論框架,提出了一種啟發式遞進的方法,實驗證明了該方法在自監督表示學習任務上對于基準方法的顯著性能提升。
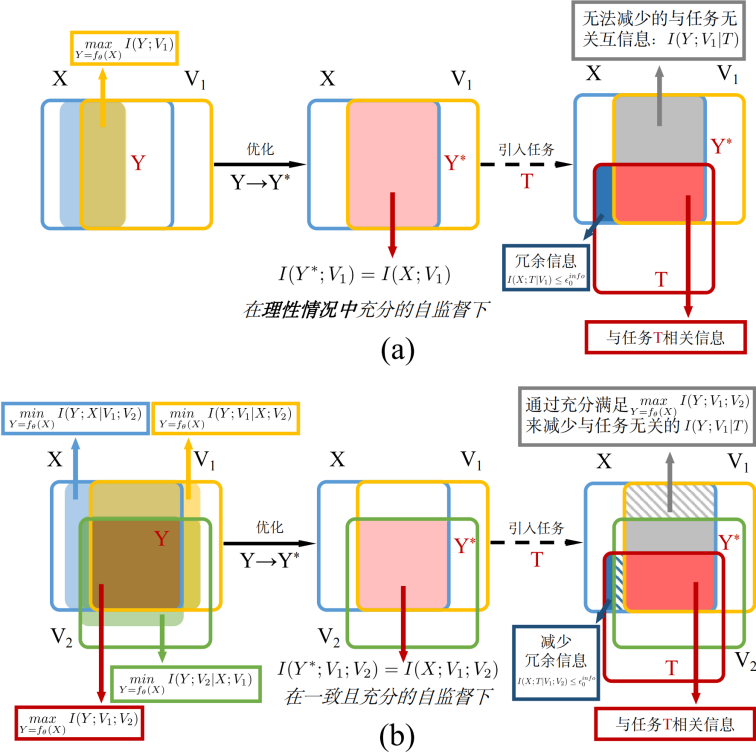
圖1:基于信息論的分析,(a)傳統自監督多視角學習方法,(b)本文提出的方法
自監督多視角表示學習方法是通過采用復雜的數據增強和特定編碼器,在視角之間進行基于錨點的對比學習。這種基于成對學習范式所得到的自監督表示會受到特定視角的噪聲、錯誤分配的假負樣本和無差別測量樣本對相似性等因素的影響。這些因素使得自監督多視角表示學習無法對多個視角的共享信息進行充分建模。
為了尋找上述因素對自監督多視角表示學習產生影響的本質原因,論文從信息論的角度進行分析,提出了一種基于信息論的泛化自監督多視角理論框架,來提升自監督多視角表示學習的可解釋性,最后總結出當前該領域所存在的問題因素影響基于錨點對比學習的三個原因:1)視角特定的噪聲導致了學習到的表示不一致; 2)錯誤分配的假負樣本導致學習過程處于有偏見的自監督下,致使學習到的表示捕獲了錯誤的判別性信息; 3)均勻測量相似度導致優化不穩定以及自監督不充分。由此,傳統自監督多視角表示學習無法對視角共享信息進行充分建模。
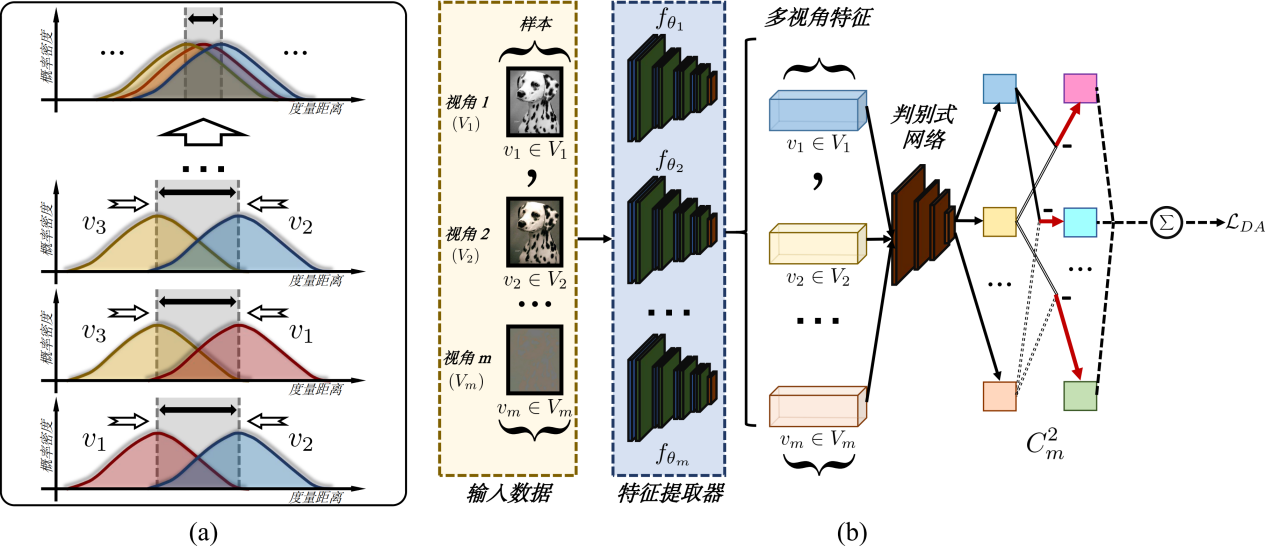
圖2:分布層的視角對齊方法,(a)視角對齊概念示意圖,(b)視角對齊算法圖
在泛化自監督多視角理論框架的指導下,論文提出了一種啟發式遞進自監督多視角編碼方法,該方法可以通過三層漸進式架構穩健地捕獲視角共享信息。在分布層中,為避免不同視角的分布偏移導致共享語義信息無法充分獲取的情況,論文通過最小化不同視角之間的差異度量(Discrepancy metric)來對齊不同視角的分布,以捕獲視角共享語義信息并屏蔽任務無關的噪聲信息。在集合層中,論文創新性地放棄了基于錨點的對比學習方法,而提出了基于池的自適應對比方法,來降低假負樣本對學習過程的負面影響。在實例層中,論文采用統一損失函數,基于對比正確的優化貢獻度來動態調整相應的梯度權重。
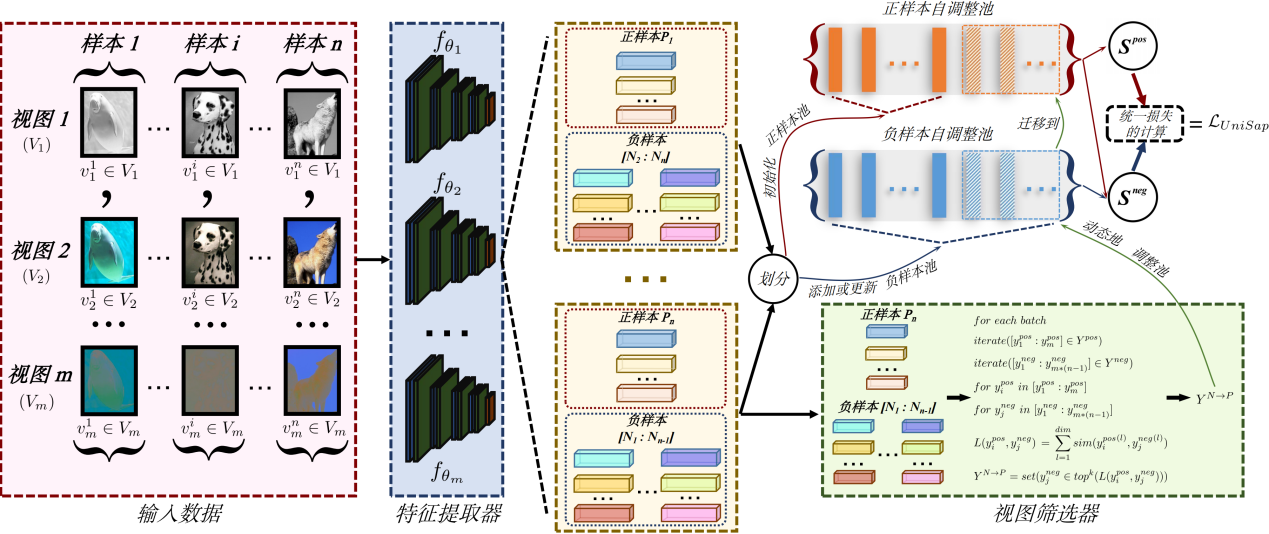
圖3:集合層與實例層算法圖
研究團隊通過理論分析證明了論文所提出的方法可以有效提高所得到的多視角表示之間互信息的下界。該方法與多種不同的自監督方法在重要圖像分類基準數據集上進行了對比(以Accuracy作為評價指標),結果表明,與最先進的基準方法相比,論文所提出的方法模型在ImageNet數據集上平均提升了1.30%,在Tiny ImageNet、CIFAR10、CIFAR100、STL-10等基準數據集上也取得了顯著的效果。
此外,研究團隊進一步在重要動作識別數據集上進行了實驗對比,并發現論文所提出的方法模型在UCF-101以及HMDB-51數據集上都達到了最先進的性能。團隊還通過消融實驗證明了所提出方法的合理性。




