軟件所在大模型驅動的自動化測試方面取得系列進展
文章來源: | 發布時間:2024-01-18 | 【打印】 【關閉】
軟件所智能博弈重點實驗室智能化軟件測試團隊,聚焦大模型驅動的軟件測試技術,解決了現實場景中復雜軟件的測試序列生成、測試用例生成和缺陷復現的系列關鍵難題,多篇研究成果被軟件工程領域CCF-A會議ICSE 2024錄用。
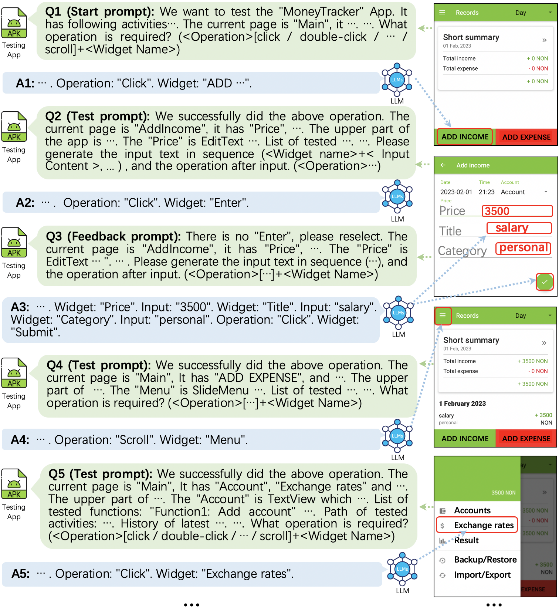
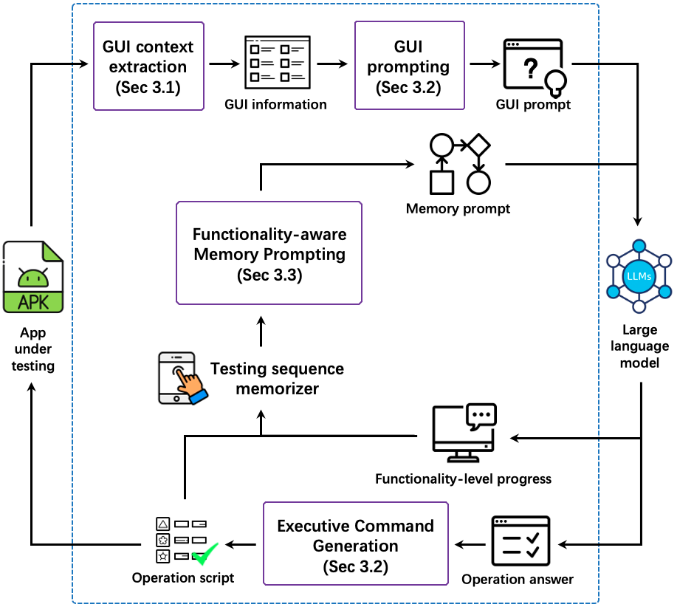
論文Make LLM a Testing Expert: Bringing Human-like Interaction to Mobile GUI Testing via Functionality-aware Decisions,第一作者為特別研究助理劉哲,通訊作者為王青研究員和王俊杰研究員。論文針對移動應用復雜業務邏輯導致的自動化測試方法存在覆蓋率低、泛化能力差等問題,利用功能感知決策的方式,模擬與測試專家交互的過程生成滿足業務邏輯的測試路徑。
團隊設計實現了GPTDroid,通過將GUI頁面信息傳遞給LLM來引發測試腳本并依次執行,不斷將應用程序測試過程中的反饋傳遞給LLM,從而實現LLM與移動應用程序交互。在這個框架內,團隊還引入了一種功能感知的記憶提示機制,使LLM能夠保留整個過程的測試知識,并進行長期的基于功能的推理來指導探索。
項目團隊在Google Play的93個應用程序上對GPTDroid進行了評估,并證明它的活動覆蓋率比最佳基線高出32%,并以更快的速度檢測到31%的缺陷。此外,GPTDroid在Google Play上發現了53個全新缺陷,其中35個已被確認并修復。
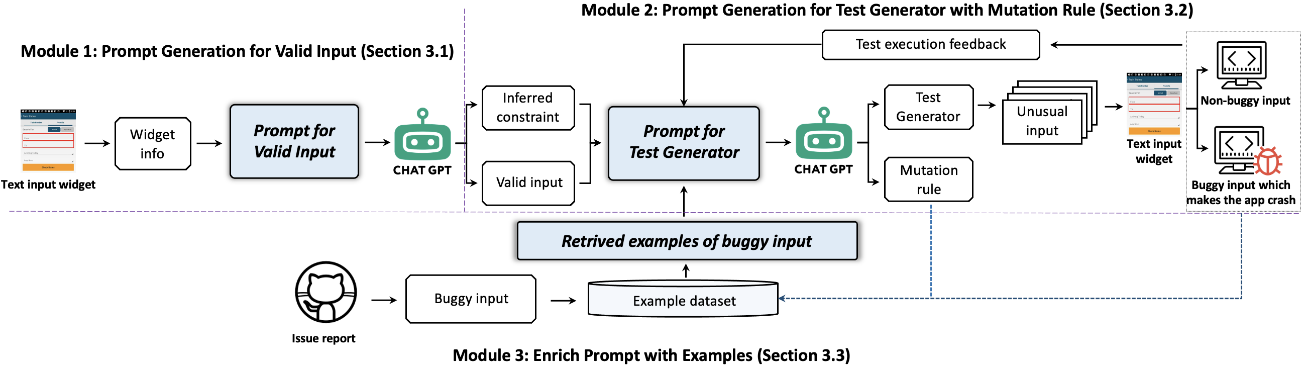
論文Testing the Limits: Unusual Text Inputs Generation for Mobile App Crash Detection with Large Language Model,第一作者為特別研究助理劉哲,通訊作者為王青研究員和王俊杰研究員。文本輸入作為用戶和應用程序之間的重要交互渠道,在搜索查詢、身份驗證、消息傳遞等核心功能中發揮著重要作用。而某些特殊的文本可能會導致應用程序崩潰,因此需要生成多樣化的異常輸入來全面測試應用程序。
團隊提出了InputBlaster,結合LLM自動生成用于移動應用程序崩潰檢測的異常文本輸入。InputBlaster將異常輸入生成問題轉化為生成一組測試生成器的任務,每個測試生成器可以在相同的突變規則下生成一批異常文本輸入。InputBlaster利用LLM與作為推理鏈的突變規則一起生成測試生成器,并利用上下文中的學習模式通過示例來演示LLM,以提高性能。
InputBlaster在31個流行應用程序的36個存在缺陷的文本輸入組件上進行了評估。結果顯示,InputBlaster達到了78%的錯誤檢測率,比最佳基線高出136%。此外,團隊也將其與流行的自動化測試工具進行集成,并從Google Play中檢測到流行App的37個全新的崩潰缺陷。
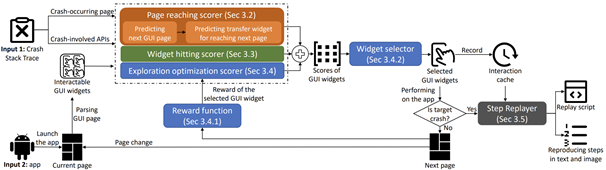
論文CrashTranslator: Automatically Reproducing Mobile Application Crashes Directly from Stack Trace,第一作者為博士生黃芋超,通訊作者為王青研究員和王俊杰研究員。論文針對應用程序崩潰復現問題,提出了一種基于大型語言模型和強化學習的自動化方法,可以根據崩潰的堆棧跟蹤來自動復現移動應用程序的崩潰。
研究團隊發現有相當一部分崩潰報告只包含了堆棧跟蹤。這些僅有堆棧跟蹤的崩潰只揭示了崩潰發生時的最后一個頁面,缺乏逐步的復現步驟。團隊針對崩潰的堆棧跟蹤,設計出了一種名為CrashTranslator的自動復現方法,它利用預訓練的大型語言模型來預測觸發崩潰的探索步驟,并設計了一種基于強化學習的技術來提供應用探索的全局引導和減少不準確的預測結果。
研究團隊在涉及58個熱門Android應用的75個崩潰報告上評估了CrashTranslator。它成功復現了61.3%的崩潰,性能超過了最先進的基準線。





 ??
??