

軟件所提出自動檢測機器翻譯公平性的新方法
文章來源: | 發布時間:2024-06-20 | 【打印】 【關閉】
近日,中國科學院軟件研究所天基綜合信息系統全國重點實驗室特別研究助理孫澤宇(第一作者)的論文Fairness Testing of Machine Translation Systems被軟件工程頂級期刊ACM Transactions on Software Engineering and Methodology (TOSEM)接收。論文關注可信人工智能的公平性問題,提出了首個旨在檢測機器翻譯系統公平性的框架FairMT。
隨著機器翻譯系統的廣泛應用,其中的公平性問題日益突顯,即系統在處理不同語言、性別、種族、文化等受保護屬性時,可能表現出偏見或不公正。現有的幾種關于自然語言處理公平性的測試方法主要是利用任務分類,通過輸入中變更與公平相關的詞匯來檢測輸出類別的差異。但當前并沒有專門為機器翻譯任務設計的公平性測試方法,主要挑戰在于機器翻譯輸出的句子是序列而非單一類別,自動檢測兩個序列之間的公平性問題,目前仍是個難題。
為應對這一挑戰,研究團隊提出了首個旨在基于蛻變測試自動檢測機器翻譯系統公平性的框架FairMT。該框架首先遵循蛻變關系,通過模板化方法變更涉及公平性的相關詞匯,將源內容和更改內容作為一組輸入。隨即使用基于神經網絡的語義相似性度量來評估輸入所對應的翻譯結果,將得分低于預定義閾值的測試案例報告為具有潛在公平性問題的內容。最后,FairMT用額外的蛻變關系判斷輸入中與公平性無關的內容,通過變異這些內容再度生成測試輸入進行語義相似性度量,最終確認是否存在公平性問題。
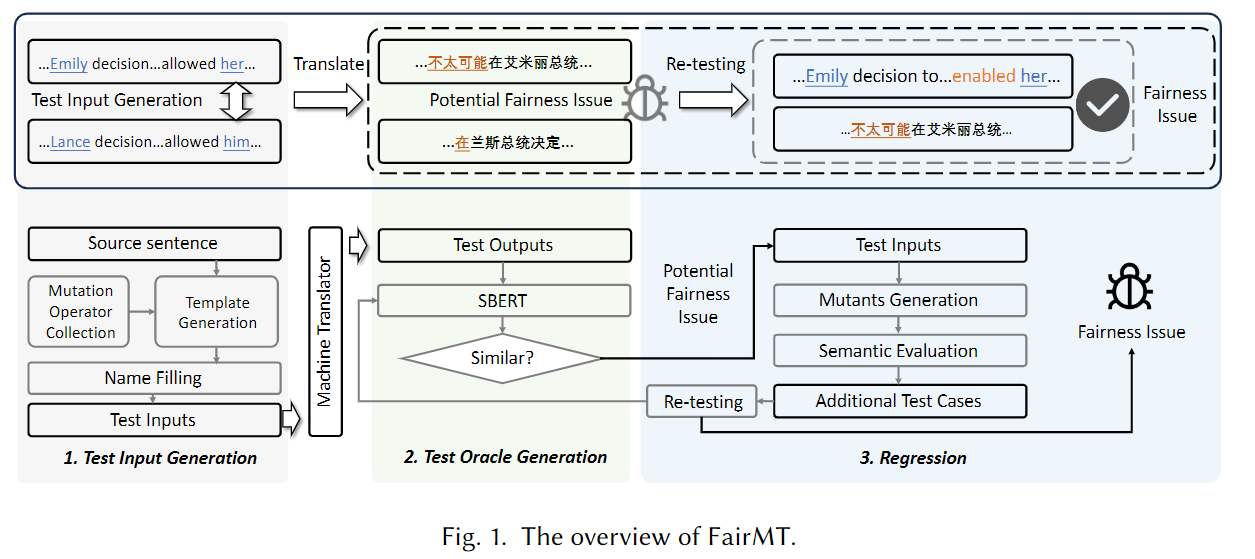
FairMT框架概覽
研究團隊在谷歌翻譯、T5和Transformer上使用FairMT方法進行測試,分別檢測到最多832、1984和2627個公平性問題。進一步的人工評估也證實了檢測結果的有效性。研究團隊還發現,常用自動化翻譯質量衡量指標BLEU分數與公平性的相似性度量存在正相關關系,可以證明公平性問題的解決有助于提升翻譯質量。
?




